个人项目介绍
本专题为个人项目介绍,目的是能够对项目快速浏览,有初步印象,如果对其感兴趣,可以进一步阅览。[TOC]
# 微信公众号App阅读模式
假如公众号的阅读体验可以选择为图书App,你会喜欢吗?
思而不得、戛然而止
**当我写作记录的时间越久的时候,越感觉在看公众号时会缺少一些东西——它一直无法让我沉浸和集中精神在内容中,无论是什么样的公众号,都有这种感觉。**后来我才慢慢发现,这种感觉就是思而不得、戛然而止。比如当你看到一篇感兴趣的推文时,想了解它的姊妹篇或获取更系统详细的内容时,需要废一番心思去其他的平台,并且经过一系列关键词检索和肉眼筛选后才能继续过瘾。
内容具有关联性
**其实,对于公众号创作者来说,内容是具有关联性的,尤其像我一样将公众号作为记录载体的人。**而公众号的模式更适合碎片化、热点追踪式、观点输出式等内容的传播。但是,公众号的模式兼容并包,对于如小说连载式的创作者来讲,一样能够作为传播的载体,只是形式上,缺少那种“感觉”。
改进的方向
**简单总结,公众号的内容有以下方面可以其他操作辅助改进:**- 内容的结构性差
公众号的内容无法一览知其详
- 沉浸式体验不高
一篇的内容不足以过读者的瘾
- 关联机制不明显
同一个系列的文章只能带话题
- 内容传播不通用
不适合小说创作者的内容传播
做出改变
**那么,如果公众号的内容能够提供一种App模式,这对于系列连载创作者,会不会更好呢?**抱着这个想法为出发点,我为自己的公众号量身定做了一款产品:ShareApp,以小程序为载体,通过内容流通,以实现模式切换。
小程序设计以简约风打造用于不同个人服务的入口,通过内容分类的选择来实现创作者的内容连载和提高内容相关性。
对于小程序的运维,只需要将每次更新的内容通过后台系统分组分模块插入对应的内容就好啦
我的小程序
- 后端:采用微信小程序云数据库,```后端0代码```前端:原生小程序开发
数据库:采用云数据库,关系型存储,读写限制
50000次/天,费用6.9RMB/月
扫码查阅我的小程序

# 分布式博客云笔记
在工作的过程中,会被动、主动的学习很多的东西,而这个过程中产生的零散的知识点,如何记录、如何展示,对我个人产生了很大的影响,为了提高工作和学习的效率,我觉得,我需要一款安全的笔记软件。
我对它的最初设想,是这样的:安全、免费、高效、便携、可读性高
我对这个还不存的笔记进行了一些梳理,我想它应该具备这些能力
在云上
笔记具备云的能力后能够让我们随时随地,无论PC还是Mobile,都能够读写笔记
分布式
笔记具备分布式的能力后无论个人还是多人的协作,都能高效的完成团队的任务
网站化
笔记具备网站的能力可以让我们具有清晰、动态的交互式体验,能够实现随时联网访问的目的
可速记
笔记具备速记能力是笔记本身核心能力的体现,也是学习和工作效率的基本要求
以上,是我对这款笔记本的能力需要,我搜遍了互联网,并没有发现一款集中以上所有优点的笔记软件,所以,我想集众家之所长,才能实现这款笔记。
Typroa 是一款高效的MarkDown编辑工具,熟练掌握它的快捷编写方式后对于实现速记的要求,基本没有任何问题,因此,我选择了它作为笔记的输入端
Git 因为其分布式协助而诞生,闻名于其分布式协助和版本控制,因此,我选择git做为笔记的管理工具
VuePress 是Vue 驱动的静态网站生成器,其内核将能够将markdown文件生成html文件,提供用户网站式的体验,因此,我选择它作为笔记的输出端
所以,将Typroa+Git+VuePress长处集成,再通过github pages的统一访问,就诞生了这款分布式博客云笔记
现在的这款产品,搭建起来比较麻烦,我想,如果有一款产品,能够集众家之长,那应该是一款成功的产品。
最后,欢迎大家访问我的分布式博客云笔记
www.滴咯哩个咚.com
www.dglgd.com
# 开发一款Maven插件
开发了一款Maven插件
入职后,公司提出了“提质增效”的口号,一个衡量质量的标准之一是统计每个开发者增、删、改的代码,并统计最终的行数。
Git 提供了很多的命令行,用来查看需要的数据,比如
git log --author="sutinghu" --since='2021-09-20' --until='2021-10-22' --pretty=tformat: --numstat | gawk '{ add += $1 ; subs += $2 ; loc += $1 + $2 } END { printf "增加的行数:%s 删除的行数:%s 总行数: %s\n",add,subs,loc }'
这种查看的方式,对于习惯命令的开发者是友好的,但是也很麻烦
如果能够有一个程序,只要设置好统计的时间,点一下就可以得到结果,那不是更好吗
秉着作为一名程序员,要有改变生活方式的理念,我决定开发一个Maven插件,只要点点点就可以实现代码的统计。
世界上所有的程序都是为了增删改查,程序里所有的逻辑都是为了处理、转移数据。
maven 也不例外,只是它的增删改查的逻辑,与一般的业务实现方式有些区别。
即“约定优于配置”,maven通过插件体系与XML配置方式将程序封装在了自己的maven体系中,这个封装后的程序被称为maven插件。
# 动手实现
# 用Java和Git交互
为了获取Git中代码的统计情况,我们需要一个Api来获取maven仓库中代码的提交情况。通过搜索大法,我发现了一个被称为Jgit的Api程序包,其核心就是通过Java程序来实现git的一系统操作。
# 用Java实现统计
前面通过GitBash统计代码的方式看起来很便携,那么代码里要如何统计呢?Git的提交是一个时间轴,也是一个栈。每次的提交都是一个入栈的过程,而时间就是每个栈元素的标签。
所以整个过程可以分为下面的几个步骤
- 查找所有的提交信息
- 过滤掉时间范围外的提交信息
- 遍历有效的提交信息
- 查找该提交信息的前一个提交信息
- 对比两次提交信息的差异
- 根据统计需要得出统计数据
- 将所有的结果进行最终的统计
# 核心的代码
# 获取所有的提交信息
public void getLogs() throws IOException, GitAPIException {
Iterable<RevCommit> commits = git.log().all().call();
List<UserCommitLog> commitLogs = new ArrayList<>();
for (RevCommit commit : commits) {
UserCommitLog userCommitLog = new UserCommitLog();
userCommitLog.setUser(commit.getAuthorIdent().getName());
userCommitLog.setCommitDate(commit.getAuthorIdent().getWhen());
userCommitLog.setRevCommit(commit);
userCommitLog.setShortMessage(commit.getShortMessage());
commitLogs.add(userCommitLog);
}
this.commitLogs = commitLogs;
}
# 获取仓库
public void initGit(){
try {
repository = new FileRepositoryBuilder()
.setGitDir(Paths.get(FileUtils.getDir(), ".git").toFile())
.build();
} catch (IOException e) {
e.printStackTrace();
}
git = new Git(repository);
try {
branch = git.getRepository().getBranch();
} catch (IOException e) {
e.printStackTrace();
}
}
# 获取用户信息
public Map<String, String> getUser(){
Map<String, String> map = new HashMap<>();
StoredConfig config = git.getRepository().getConfig();
String username = config.getString("user", null, "name");
String email = config.getString("user", null, "email");
map.put("username",username);
map.put("email",email);
return map;
}
# 获取每次提交的详情
public static List<DiffEntry> getChangedFileList(RevCommit revCommit, Repository repo) {
List<DiffEntry> returnDiffs = null;
try {
RevCommit previsouCommit=getPrevHash(revCommit,repo);
if(previsouCommit==null) {
return null;
}
ObjectId head=revCommit.getTree().getId();
ObjectId oldHead=previsouCommit.getTree().getId();
// prepare the two iterators to compute the diff between
try (ObjectReader reader = repo.newObjectReader()) {
CanonicalTreeParser oldTreeIter = new CanonicalTreeParser();
oldTreeIter.reset(reader, oldHead);
CanonicalTreeParser newTreeIter = new CanonicalTreeParser();
newTreeIter.reset(reader, head);
// finally get the list of changed files
try (Git git = new Git(repo)) {
List<DiffEntry> diffs= git.diff()
.setNewTree(newTreeIter)
.setOldTree(oldTreeIter)
.call();
returnDiffs=diffs;
} catch (GitAPIException e) {
e.printStackTrace();
}
}
} catch (IOException e) {
e.printStackTrace();
}
return returnDiffs;
}
# 获取前一次提交
public static RevCommit getPrevHash(RevCommit commit, Repository repo) throws IOException {
try (RevWalk walk = new RevWalk(repo)) {
// Starting point
walk.markStart(commit);
int count = 0;
for (RevCommit rev : walk) {
// got the previous commit.
if (count == 1) {
return rev;
}
count++;
}
walk.dispose();
}
//Reached end and no previous commits.
return null;
}
# 对差异做统计
public void countDiff(RevCommit commit,UserCount userCount){
String versionTag= commit.getName();
try {
RevWalk walk = new RevWalk(repository);
ObjectId versionId=repository.resolve(versionTag);
RevCommit verCommit=walk.parseCommit(versionId);
List<DiffEntry> diffFix=getChangedFileList(verCommit,this.repository);
ByteArrayOutputStream out = new ByteArrayOutputStream();
DiffFormatter df = new DiffFormatter(out);
df.setRepository(this.repository);
int addSize = 0;
int subSize = 0;
int allsize = 0;
for (DiffEntry entry : diffFix) {
df.format(entry);
FileHeader fileHeader = df.toFileHeader(entry);
List<HunkHeader> hunks = (List<HunkHeader>) fileHeader.getHunks();
for(HunkHeader hunkHeader:hunks){
EditList editList = hunkHeader.toEditList();
for(Edit edit : editList){
subSize += edit.getEndA()-edit.getBeginA();
addSize += edit.getEndB()-edit.getBeginB();
allsize += edit.getEndA()-edit.getBeginA() + edit.getEndB()-edit.getBeginB();
}
}
out.reset();
}
userCount.setAddSize(addSize);
userCount.setSubSize(subSize);
userCount.setAllSize(allsize);
}
catch (IOException e) {
e.printStackTrace();
}
}
# 使用
最后,如果你想使用这个插件,只需要三个步骤
- 将插件程序包放入自己的仓库
https://github.com/sutinghu153/maven-plugin-gitcodes-count
以上是程序包的下载路径,只需要sutinghu.zip即可
- 在项目的顶层POM文件中进行配置
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-plugin-plugin</artifactId>
<version>3.5.2</version>
</plugin>
<plugin>
<!-- 指定maven编译的jdk版本 -->
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<verbose>true</verbose>
<fork>true</fork>
<!--你的jdk地址-->
<executable>C:/Program Files/Java/jdk1.8.0_20/bin/javac</executable>
<source>8</source>
<target>8</target>
</configuration>
</plugin>
<plugin>
<groupId>sutinghu.tools</groupId>
<artifactId>countcodes-maven-plugin</artifactId>
<version>1.0.0</version>
<configuration>
<type>me</type>
<startTime>2020-02-01</startTime>
<endTime>2021-12-01</endTime>
</configuration>
</plugin>
</plugins>
</build>
参数说明
type用来选择查看哪些用户的代码统计结果,默认为 me
- me 仅自己
- all 所有用户
startTime用来设置开始时间
endTime用来设置结束时间
- 在IDEA中的maven插件管理工具中运行
count codes:count
# 模板填充组件
# 关于组件
# 01 业务场景
在资规系统中,使用者对文件及格式规范具有严格要求,比如会议纪要生成的文件,各种事务的文件以及数据分析后的数据报表。

图(1)工作效率完成情况模板

图(2)表格模板
#### 02 现行系统的模板开发及管理模式在之前的系统业务开发中,模板文件的开发和管理表现为以下特点:
模板管理混乱
模板管理混乱表现为,有些模板的管理通过数据库缓存,有些模板直接打包在jar服务中,有些模板通过file服务调用。
混乱的模板管理给系统的维护和实施人员带来了一些不必要的挑战和麻烦,比如对系统不熟悉时,可能忽视部分模板的管理,从而解决一些不必要的bug。
对接流程繁杂
当每一个具有使用模板的需求提出时,开发人员都需要经过以下的环节
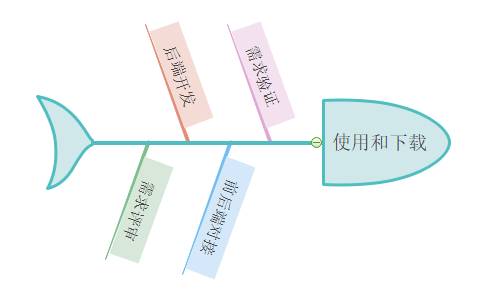
以上,每次具有模板填充相关的需求都是一次折腾,而这种折腾可以通过环节规范和统一来优化,缩小该过程的时间,提高对接的效率。
不能立即响应
在以上的方式中,每次同类需求的完成、验证和发布,都需要开发人员重新打包、实施人员重新发包,多余的环节有可能造成实施故障,并且笨拙的方式使得客户的需求不能立即响应。
时间久内存消耗大
我看了每个填充模板的代码逻辑,都使用了N多个内部循环,多条件循环,模板的生成因而影响系统的性能,消耗内存,且复杂模板的填充用时太久。
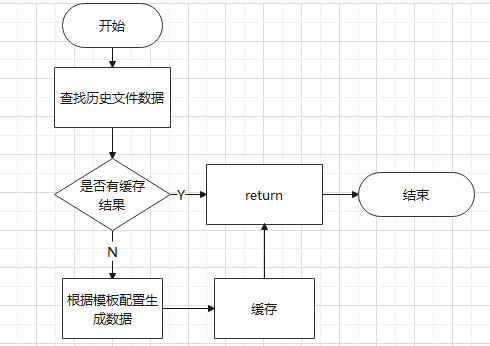
# 03 解决方案
模板填充组件,是基于sql语句和规范对复杂的word或excel模板进行填充的一套通用代码,它在大监管工作效率月报及考核指标相关文件报表的展示及导出下载方面显示出重要的作用和极高的使用性。
为了提高大监管开发效率,我设计了Word及excel的模板填充组件,该组件基于sql的查询和配置,能够极大减少代码内部循环,快速填充模板,组件支持word表格、word字段、word图表、excel数据的填充。
核心逻辑如下:
# 组件的诞生历程
# 01 通过规范以动制静
# 目标
为了实现后期模板填充的基础代码的0改动,必须有一套实用的规范,实现数据动态插入。
为了实现以上目标,将数据库查询结果直接插入模板中,SQL的配置设计了相关规范(规范及sql示例详见附录)。
# 核心逻辑
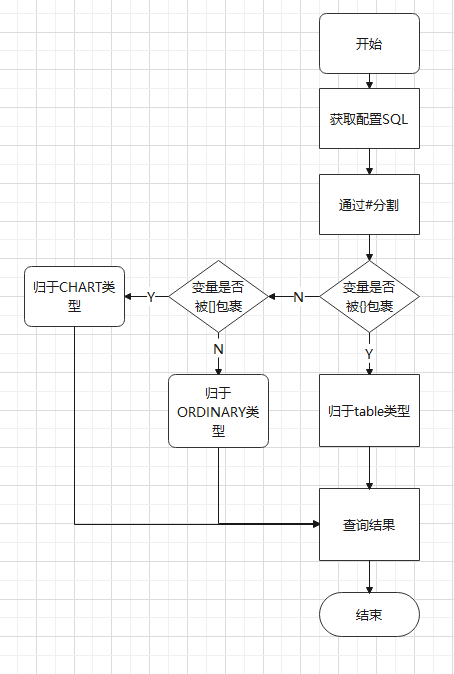
# 核心代码
核心代码详见附录
# 结果
基于以上方法,当我们获取对应模板的sql语句后,只需要执行以下语句,即可得到模板需要的构造值。
// 获取实体
JcTemplateConfig jcTemplateConfig = this.getEntity(templateId);
// 获取数据
List<Map<String, Object>> mapData = feildDataService.buildTemplateData(jcTemplateConfig.getTemplateSql());
# 02 文档表格多源支持
# 目标
为了使组件能够兼容word及excel等不同类型的文件填充,需要将对应模板进行分类,并在代码中实现分流。
# 核心代码
if (Objects.equals(WORD,wordOrExcel)) {
return this.getWordHistory(templeteId, fileType, year, month, day);
}else if (Objects.equals(EXCEL,wordOrExcel)) {
return this.getExcelHistory(templeteId, fileType, year, month, day);
}else {throw new DeclareException("不存在的类型");}
# 03 图文表数应有尽有
# 目标
在word或excel的模板填充中,会涉及到图表如柱状图、饼图等的填充及excel表格的填充,在正确配置sql后,组件将在模板处理中,自动对对应的图表等进行填充。
# 核心代码
核心代码详见附录
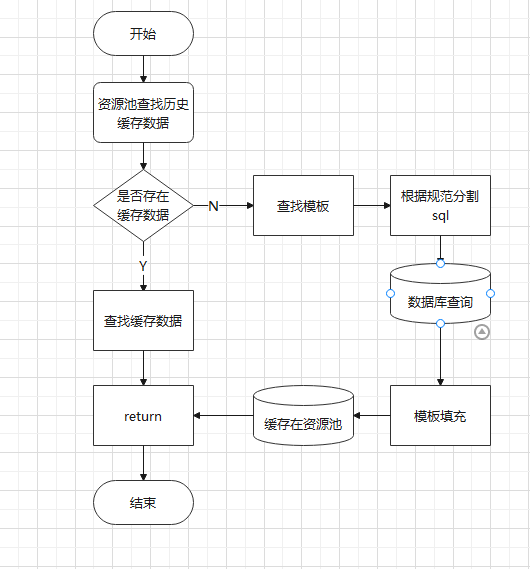
# 04 用资源池闭源节流
# 目标
复杂的模板,会在数据库查询多条sql,这会增大数据库的压力,因此设计资源池,使得研发人员通过接口调用可以实现每个模板按年、按月、按日获取唯一缓存数据,从而降低模板sql查询批次。
# 核心逻辑
# 核心代码
// 校验
historicWordsService.checkDataAvailability(templeteId);
// 获取历史缓存数据
JcHistoricWords words = historicWordsService.getWordsByTemplateId(templeteId, fileType, year, month, day);
# 推广使用的意义
- 对模板进行统一管理,降低维护成本
- 动态管理sql,快速响应用户需求
- 减少对接环节,提高工作效率
- 快速验证,不必打包发布
- 规范使用接口,提高前后端对接效率
# 组件后期的优化
# 优化SQL
当前模板填充版本基于大量sql,有些sql复杂性较高,考虑以视图方式缓存数据,提高sql查询。
# 定制化配置
当用户只需要查询某具体时间段的数据时,需要配置startTime及endTime字段,而一些具有特殊需求的模板,也应该增加对应的配置项,这种配置项在后期的使用中将逐一完善。
# 附录
# sql规范
| 符号 | 作用 | |
|---|---|---|
| # | 用来分割每个完成的查询sql | |
| [] | 如果你想生成图表,可以将你想展示的图表名用[]包裹 | |
| {} | 如果你想插入一个表格数据,可以用{}将对应数组的名称用{}包裹 | |
| ; | 用来分割每个可执行的sql |
# SQL示例
# 普通SQL
SELECT COUNT(*) as FWBJ FROM doc_entity WHERE doc_entity.script_type = 2 AND doc_entity.key_num_gather IS NOT NULL and doc_entity.op_state = 5;#
# 表格SQL
SELECT
city_assess_id AS INDEX,
assess_project AS prj,
assess_indicative AS zhibiao,
indicative_nature as xinzhi,
score as fenzhi,
inspection_points as content,
duty_office_depart as depart,
match_office_depart as depart2,
duty_leader as leader,
assess_performance as state,
'无' as remark,
update_time as shijian
FROM
jc_urban_assessment;{table}#
# 图表SQL
SELECT
city_assess_id AS INDEX,
assess_project AS prj,
assess_indicative AS zhibiao,
indicative_nature as xinzhi,
score as fenzhi,
inspection_points as content,
duty_office_depart as depart,
match_office_depart as depart2,
duty_leader as leader,
assess_performance as state,
'无' as remark,
update_time as shijian
FROM
jc_urban_assessment;[table]#
# 核心代码
# 数据填充核心代码
if(Objects.equals(e.get("TYPE"),FeildTypeEnum.ORDINARY.getDesc())) {
Map<String, Object> map = new HashMap<>(2);
map.put("TYPE",FeildTypeEnum.ORDINARY.getDesc());
map.put("VALUE",sqlByMapService.getTemplateOrdinary(e.get("SQL")));resultData.add(map);
}if(Objects.equals(e.get("TYPE"),FeildTypeEnum.ORDINARY.getDesc())) {
Map<String, Object> map = new HashMap<>(2);
map.put("TYPE",FeildTypeEnum.ORDINARY.getDesc());
map.put("VALUE",sqlByMapService.getTemplateOrdinary(e.get("SQL")));resultData.add(map);
}if(Objects.equals(e.get("TYPE"),FeildTypeEnum.ORDINARY.getDesc())) {
Map<String, Object> map = new HashMap<>(2);
map.put("TYPE",FeildTypeEnum.ORDINARY.getDesc());
map.put("VALUE",sqlByMapService.getTemplateOrdinary(e.get("SQL")));
resultData.add(map);
}
# sql分割核心代码
// 存在表中表结构
if (string.contains(ConstantJiance.CHECK_CUR_LEFT) && string.contains(ConstantJiance.CHECK_CUR_RIGHT)) {
map.put("TYPE", FeildTypeEnum.TABLE.getDesc());
String[] sqls = string.split(ConstantJiance.CUR_LEFT);
map.put("SQL",sqls[0]);
map.put("TABLE_NAME",sqls[1].split(ConstantJiance.CUR_RIGHT)[0]);// 普通字段
}else if (!string.contains(ConstantJiance.CHECK_CUR_LEFT) && !string.contains(ConstantJiance.CHECK_CUR_RIGHT)) {
map.put("TYPE", FeildTypeEnum.ORDINARY.getDesc());
map.put("SQL",string);}else if (string.contains(ConstantJiance.CHECK_TABLE_CUR_LEFT) && string.contains(ConstantJiance.CHECK_TABLE_CUR_RIGHT)){
map.put("TYPE", FeildTypeEnum.CHART.getDesc());String[] sqls = string.split(ConstantJiance.CUR_TABLE_LEFT);
map.put("SQL",sqls[0]);map.put("CHART_NAME",sqls[1].split(ConstantJiance.CUR_TABLE_RIGHT)[0]);
}else {throw new DeclareException("异常SQL,请重新配置");}
# 图文填充核心代码
/**
* 功能描述: 根据要填充的类型 对内容进行填充WORD
* @author sutinghu
* @date
* @param file
* @param list 参数
* @return byte[]
*/
@SneakyThrows
public static byte[] buildTemplateWord(byte[] file, List<Map<String, Object>> list){
if (CollectionUtils.isEmpty(list)) {
return file;
}
byte[] fileResult = file;
for (Map<String, Object> map : list) {
String type = (String) map.get("TYPE");
Object value = map.get("VALUE");
// 填充的内容是普通字段
if(Objects.equals(FeildTypeEnum.ORDINARY.getDesc(),type)){if (value instanceof Map) {Map<String, Object> valueOrdinaty = (Map<String, Object>) value;fileResult = fillWordDataByMap(fileResult, valueOrdinaty);}
// 填充的内容是普通表格
}else if(Objects.equals(FeildTypeEnum.TABLE.getDesc(),type)){
String tableName = (String) map.get("TABLE_NAME");
if (value instanceof List) {fileResult = fillWordDataByMap(fileResult,new HashMap<String, Object>(2) {{ put(tableName,value);}});}// 填充的内容是普通图表
}else if(Objects.equals(FeildTypeEnum.CHART.getDesc(),type)){
String tableName = (String) map.get("CHART_NAME");
if (value instanceof List) {
List<Map<String, Object>> list1 = (List<Map<String, Object>>) value;
fileResult = fillWordChartByMap(fileResult,list1,tableName);
}
}
}
return fileResult;
}
# 简易FTP服务设计与实现
# 什么是FTP服务?
互联网上提供文件(存储)和访问服务的(计算机),它们依照FTP协议 (opens new window)提供服务。 FTP是File Transfer Protocol(文件传输协议)。顾名思义,就是专门用来传输文件的协议。简单地说,支持FTP协议的服务器就是FTP服务器。
FTP服务分为服务器(Server)和客户机(Client)两个角色。FTP服务器使用的端口是21端口和20端口,21端口用于服务器和客户机建立命令的链路,20端口用于服务器向客户机建立数据链路。
# FTP的作用
- 用来在两台计算机之间传输文件
- 具有跨平台的特性
- 网络中经常采用的资源共享方式之一
# FTP协议
FTP(File Transfer Protocol)即文件传输协议,是一种基于TCP的协议,采用客户/服务器模式。 通过FTP协议,用户可以在FTP服务器中进行文件的上传或下载等操作。
# FTP的特点
- FTP使用两个平行连接:控制连接和数据连接。控制连接在两主机间传送控制命令,如用户身份、口令、改变目录命令等。数据连接只用于传送数据。
- 在一个会话期间,FTP服务器必须维持用户状态,也就是说,和某一个用户的控制连接不能断开。另外,当用户在目录树中活动时,服务器必须追踪用户的当前目录,这样,FTP就限制了并发用户数量。
- FTP支持文件沿任意方向传输。当用户与一远程计算机建立连接后,用户可以获得一个远程文件也可以将一本地文件传输至远程机器。
# FTP服务的传输模式
FTP传输模式分别为主动模式和被动模式
- 主动模式是服务器主动连接客户机并建立数据链路
- 被动模式是服务器等待客户机建立数据链路

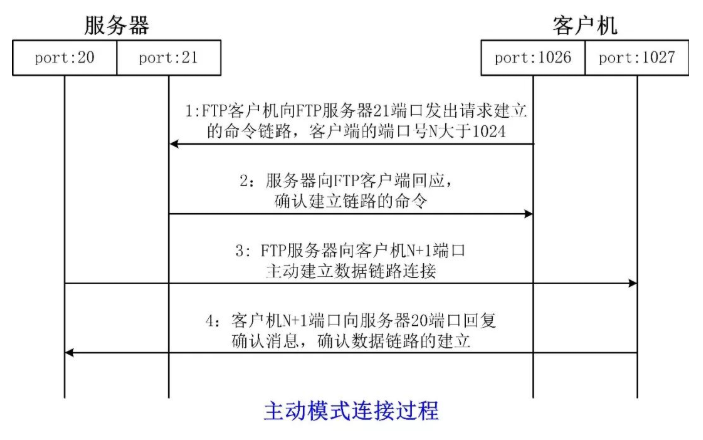
# TCP/UDP协议
# UDP协议
# 特征
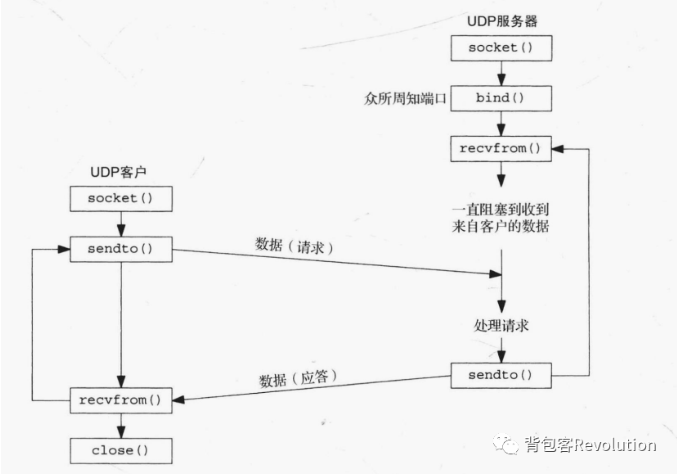
UDP是面向无连接的协议。
UDP使用数据报套接字(Datagram Socket)进行通信,因为数据报有长度,所以传输的消息有记录边界。
应用进程发送的消息被封装到UDP数据报,UDP数据报被封装到IP数据报,最终的数据报被发送到目的地。
UDP缺乏可靠性,不能保证数据一定能送达,也不能保证数据被送达的频次和先后顺序。
# 流程
客户端:socket()->bind()->sendto()->recvfrom()->close() //客户端可以不用bind()
服务器:socket()->bind()->recvfrom()->sendto()->close()
# TCP协议
# 简介
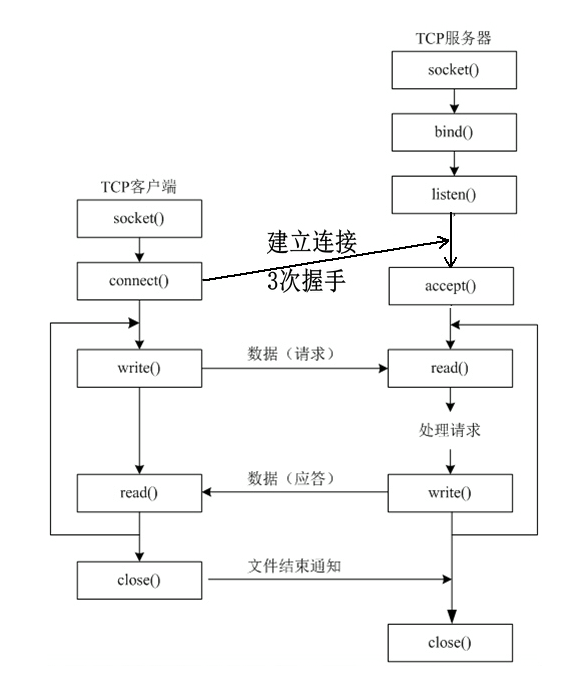
- TCP是面向连接的协议,建立连接的过程有三次握手和四次握手。
- TCP使用流套接字(Stream Socket)进行通信,因为流没有长度,所以传输的消息没有记录边界。
- 客户端使用TCP协议与服务器进行通信时,需要先建立连接,然后才能进行数据交换。
- TCP提供了消息确认和重传机制,保证了传输的可靠性。
- TCP提供了流量控制,流量控制的大小取决于接收缓冲区可用空间的大小。客户端发送一次数据,接收缓冲区可用空间变小。服务器接收一次数据,接收缓冲区可用空间变大。
- TCP连接为全双工通信,而UDP既可以全双工通信,也可以使用别的通信模式。
# 连接模式
通信的两种模式:SYN & ACK
SYN:用来发送新信号
ACK:用来返回确认信号
# 建立连接
1.找个可以通话的手机(socket() )
2.拨通对方号码并确定对方是自己要找的人( connect() )
3.主动聊天( send() 或 write() )
4.或者,接收对方的回话( recv() 或read() )
5.通信结束后,双方说再见挂电话(close() )
# 流程
- 三次握手和四次握手主要发生在connect/accept阶段。
客户端:socket()------------------->connect()->I/O操作->close()
服务器:socket()->bind()->listen()->accept()->I/O操作->close()
# FTP 被动模式服务端设计
# 流程设计
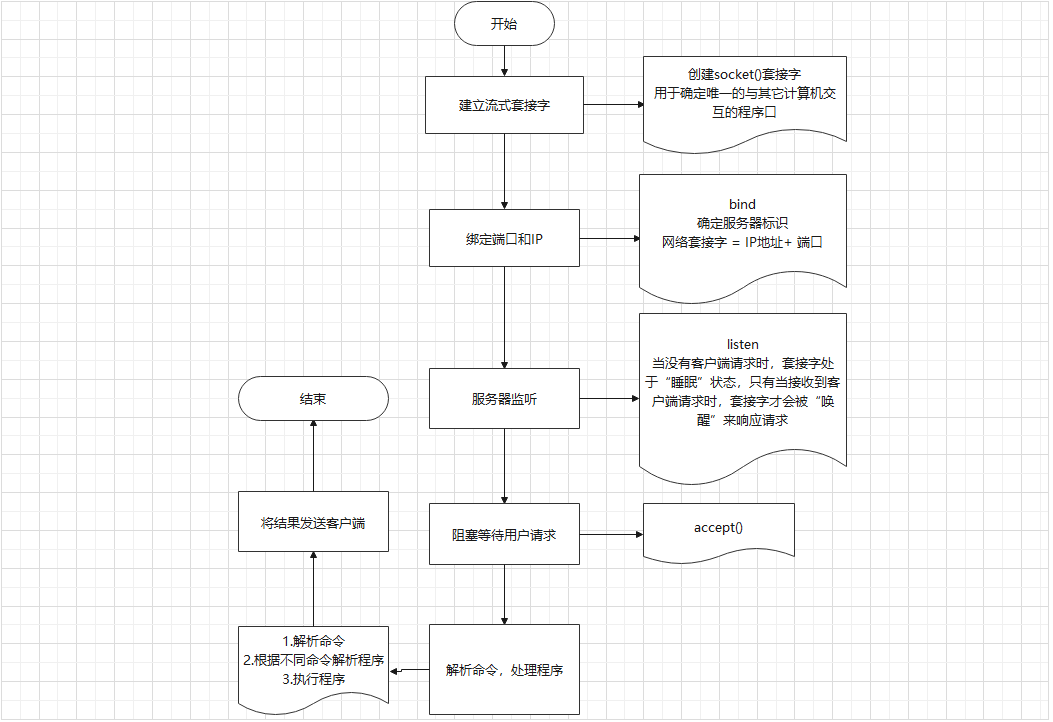
# 代码实现
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#include <dirent.h>
#include <fcntl.h>
#define N 256//文件名和命令名最长为256字节
// 查看文件命令
void commd_ls(int);
// 下载文件
void commd_get(int, char *);
// 上传文件
void commd_put(int, char *);
int main(int arg, char *argv[])
{
int ser_sockfd,cli_sockfd;// 服务端和客户端的套接字文件描述符
struct sockaddr_in ser_addr,cli_addr;// 服务端和客户端的套接字文件结构体
int ser_len, cli_len;// 结构体长度
char commd [N];
bzero(commd,N);//将commd所指向的字符串的前N个字节置为0,包括'\0'
if((ser_sockfd=socket(AF_INET, SOCK_STREAM, 0) ) < 0)
{
printf("Sokcet Error!\n");
return -1;
}
bzero(&ser_addr,sizeof(ser_addr));
ser_addr.sin_family = AF_INET;
ser_addr.sin_addr.s_addr = htonl(INADDR_ANY);//本地ip地址
ser_addr.sin_port = htons (8989);//转换成网络字节
ser_len = sizeof(ser_addr);
//将ip地址与套接字绑定
if((bind(ser_sockfd, (struct sockaddr *)&ser_addr, ser_len)) < 0)
{
printf("Bind Error!\n");
return -1;
}
//服务器端监听
if(listen(ser_sockfd, 5) < 0)
{
printf("Linsten Error!\n");
return -1;
}
bzero(&cli_addr, sizeof(cli_addr));
ser_len = sizeof(cli_addr);
while(1)
{
printf("server>");
//服务器端接受来自客户端的连接,返回一个套接字,此套接字为新建的一个,并将客户端的地址等信息存入cli_addr中
//原来的套接字仍处于监听中
if((cli_sockfd=accept(ser_sockfd, (struct sockaddr *)&cli_addr, &cli_len)) < 0)
{
printf("Accept Error!\n");
exit(1);
}
//由套接字接收数据时,套接字把接收的数据放在套接字缓冲区,再由用户程序把它们复制到用户缓冲区,然后由read函数读取
//write函数同理
if(read(cli_sockfd, commd, N) < 0) //read函数从cli_sockfd中读取N个字节数据放入commd中
{
printf("Read Error!\n");
exit(1);
}
printf("recvd [ %s ]\n",commd);
if(strncmp(commd,"ls",2) == 0)
{
commd_ls(cli_sockfd);
}else if(strncmp(commd,"get", 3) == 0 )
{
commd_get(cli_sockfd, commd+4);
}else if(strncmp(commd, "put", 3) == 0)
{
commd_put(cli_sockfd, commd+4);
}else
{
printf("Error!Command Error!\n");
}
}
return 0;
}
/*
**显示文件列表
*/
void commd_ls(int sockfd)
{
DIR * mydir =NULL;
struct dirent *myitem = NULL;
char commd[N] ;
bzero(commd, N);
//opendir为用来打开参数name 指定的目录, 并返回DIR*形态的目录流
//mydir中存有相关目录的信息
if((mydir=opendir(".")) == NULL)
{
printf("OpenDir Error!\n");
exit(1);
}
while((myitem = readdir(mydir)) != NULL)//用来读取目录,返回是dirent结构体指针
{
if(sprintf(commd, myitem->d_name, N) < 0)//把文件名写入commd指向的缓冲区
{
printf("Sprintf Error!\n");
exit(1);
}
if(write(sockfd, commd, N) < 0 )//将commd缓冲区的内容发送会client
{
printf("Write Error!\n");
exit(1);
}
}
closedir(mydir);//关闭目录流
close(sockfd);
return ;
}
/*
**实现文件的下载
*/
void commd_get(int sockfd, char *filename)
{
int fd, nbytes;
char buffer[N];
bzero(buffer, N);
printf("get filename : [ %s ]\n",filename);
if((fd=open(filename, O_RDONLY)) < 0)//以只读的方式打开client要下载的文件
{
printf("Open file Error!\n");
buffer[0]='N';
if(write(sockfd, buffer, N) <0)
{
printf("Write Error!At commd_get 1\n");
exit(1);
}
return ;
}
buffer[0] = 'Y'; //此处标示出文件读取成功
if(write(sockfd, buffer, N) <0)
{
printf("Write Error! At commd_get 2!\n");
close(fd);
exit(1);
}
while((nbytes=read(fd, buffer, N)) > 0)//将文件内容读到buffer中
{
if(write(sockfd, buffer, nbytes) < 0)//将buffer发送回client
{
printf("Write Error! At commd_get 3!\n");
close(fd);
exit(1);
}
}
close(fd);
close(sockfd);
return ;
}
/*
**实现文件的上传
*/
void commd_put(int sockfd, char *filename)
{
int fd, nbytes;
char buffer[N];
bzero(buffer, N);
printf("get filename : [ %s ]\n",filename);
if((fd=open(filename, O_WRONLY|O_CREAT|O_TRUNC, 0644)) < 0)//以只写的方式打开文件,若文件存在则清空,若文件不存在则新建文件
{
printf("Open file Error!\n");
return ;
}
while((nbytes=read(sockfd, buffer, N)) > 0)//将client发送的文件写入buffer
{
if(write(fd, buffer, nbytes) < 0)//将buffer中的内容写到文件中
{
printf("Write Error! At commd_put 1!\n");
close(fd);
exit(1);
}
}
close(fd);
close(sockfd);
return ;
}
# FTP被动模式客户端设计
# 流程设计
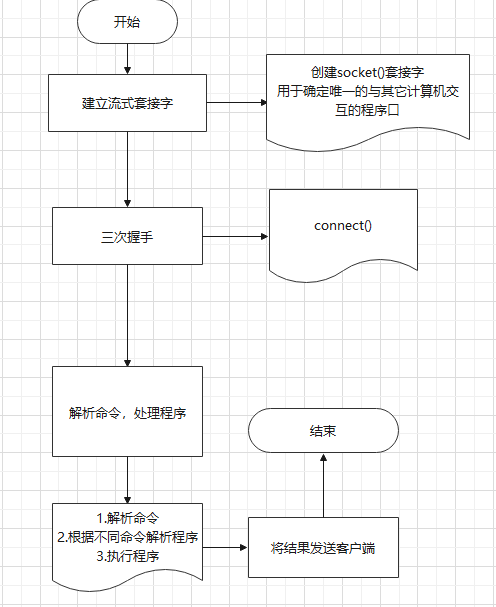
# 代码实现
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#include <netinet/in.h>
#include <fcntl.h>
#define N 256
void commd_help();
void commd_exit();
void commd_ls(struct sockaddr_in, char *);
void commd_get(struct sockaddr_in , char *);
void commd_put(struct sockaddr_in , char *);
int main(int argc, char *argv[])
{
char commd[N];
struct sockaddr_in addr;
int len;
bzero(&addr, sizeof(addr)); //将&addr中的前sizeof(addr)字节置为0,包括'\0'
addr.sin_family = AF_INET; //AF_INET代表TCP/IP协议
addr.sin_addr.s_addr = inet_addr("127.0.0.1"); //将点间隔地址转换为网络字节顺序
addr.sin_port = htons(8989); //转换为网络字节顺序
len = sizeof(addr);
while(1)
{
printf("ftp>");
bzero(commd,N);
//fgets函数从stdin流中读取N-1个字符放入commd中
if(fgets(commd,N,stdin) == NULL)
{
printf("Fgets Error!\n");
return -1;
}
commd[strlen(commd)-1]='\0'; //fgets函数读取的最后一个字符为换行符,此处将其替换为'\0'
printf("Input Command Is [ %s ]\n",commd);
if(strncmp(commd,"help",4) == 0) //比较两个字符串前4个字节,若相等则返回0
{
commd_help();
}else if(strncmp(commd, "exit",4) == 0)
{
commd_exit();
exit(0); //结束进程
}else if(strncmp(commd, "ls" , 2) == 0)
{
commd_ls(addr, commd);
}else if(strncmp(commd, "get" , 3) == 0)
{
commd_get(addr, commd);
}else if(strncmp(commd, "put", 3) ==0 )
{
commd_put(addr, commd);
}else
{
printf("Command Is Error!Please Try Again!\n");
}
}
return 0;
}
/*
**帮助信息
*/
void commd_help()
{
printf("\n=---------------------欢迎使用FTP--------------------------|\n");
printf("| |\n");
printf("| help:View all commands |\n");
printf("| |\n");
printf("| exit:Disconnect |\n");
printf("| |\n");
printf("| ls : Displays a list of files for the FTP server|\n");
printf("| |\n");
printf("| get <file>:Download files from FTP server |\n");
printf("| |\n");
printf("| put <file>:Transfer files to FTP server |\n");
printf("| |\n");
printf("|------------------------------------------------------------|\n");
return ;
}
/*
**退出FTP服务器
*/
void commd_exit()
{
printf("Bye!\n");
}
/*
**显示文件列表
*/
void commd_ls(struct sockaddr_in addr, char *commd)
{
int sockfd;
//创建套接字
if((sockfd=socket(AF_INET, SOCK_STREAM, 0)) < 0)
{
printf("Socket Error!\n");
exit(1);
}
if(connect(sockfd, (struct sockaddr *)&addr, sizeof(addr)) < 0)
{
printf("Connect Error!\n");
exit(1);
}
//将commd指向的内容写入到sockfd所指的文件中,此处即指套接字
if(write(sockfd, commd, N) < 0)
{
printf("Write Error!\n");
exit(1);
}
while(read(sockfd, commd, N) > 0) //从sockfd中读取N字节内容放入commd中,
{ //返回值为读取的字节数
printf(" %s ",commd);
}
printf("\n");
close(sockfd);
return ;
}
/*
**实现文件的下载
*/
void commd_get(struct sockaddr_in addr, char *commd)
{
int fd;
int sockfd;
char buffer[N];
int nbytes;
//创建套接字,并进行错误检测
if((sockfd=socket(AF_INET, SOCK_STREAM, 0)) < 0)
{
printf("Socket Error!\n");
exit(1);
}
//connect函数用于实现客户端与服务端的连接,此处还进行了错误检测
if(connect(sockfd, (struct sockaddr *)&addr, sizeof(addr)) < 0)
{
printf("Connect Error!\n");
exit(1);
}
//通过write函数向服务端发送数据
if(write(sockfd, commd, N) < 0)
{
printf("Write Error!At commd_get 1\n");
exit(1);
}
//利用read函数来接受服务器发来的数据
if(read(sockfd, buffer, N) < 0)
{
printf("Read Error!At commd_get 1\n");
exit(1);
}
//用于检测服务器端文件是否打开成功
if(buffer[0] =='N')
{
close(sockfd);
printf("Can't Open The File!\n");
return ;
}
//open函数创建一个文件,文件地址为(commd+4),该地址从命令行输入获取
if((fd=open(commd+4, O_WRONLY|O_CREAT|O_TRUNC, 0644)) < 0)
{
printf("Open Error!\n");
exit(1);
}
//read函数从套接字中获取N字节数据放入buffer中,返回值为读取的字节数
while((nbytes=read(sockfd, buffer, N)) > 0)
{
//write函数将buffer中的内容读取出来写入fd所指向的文件,返回值为实际写入的字节数
if(write(fd, buffer, nbytes) < 0)
{
printf("Write Error!At commd_get 2");
}
}
close(fd);
close(sockfd);
return ;
}
/*
**实现文件的上传
*/
void commd_put(struct sockaddr_in addr, char *commd)
{
int fd;
int sockfd;
char buffer[N];
int nbytes;
//创建套接字
if((sockfd=socket(AF_INET, SOCK_STREAM, 0)) < 0)
{
printf("Socket Error!\n");
exit(1);
}
//客户端与服务端连接
if(connect(sockfd, (struct sockaddr *)&addr, sizeof(addr)) < 0)
{
printf("Connect Error!\n");
exit(1);
}
//从commd中读取N字节数据,写入套接字中
if(write(sockfd, commd, N)<0)
{
printf("Wrtie Error!At commd_put 1\n");
exit(1);
}
//open函数从(commd+4)中,读取文件路径,以只读的方式打开
if((fd=open(commd+4, O_RDONLY)) < 0)
{
printf("Open Error!\n");
exit(1);
}
//从fd指向的文件中读取N个字节数据
while((nbytes=read(fd, buffer, N)) > 0)
{
//从buffer中读取nbytes字节数据,写入套接字中
if(write(sockfd, buffer, nbytes) < 0)
{
printf("Write Error!At commd_put 2");
}
}
close(fd);
close(sockfd);
return ;
}
# 结果
# 执行help命令
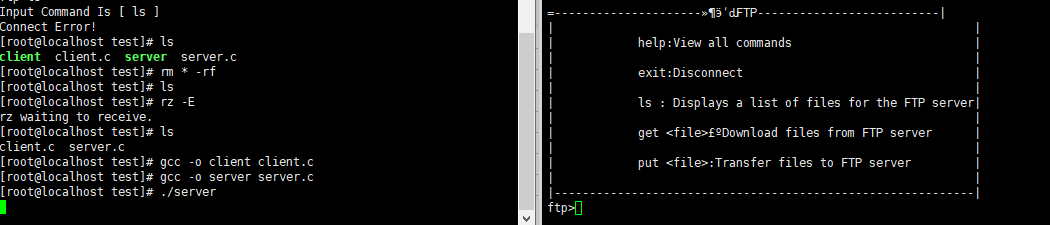
# 执行ls命令

# Shell监控脚本
# 引入
平时在进行服务端开发时,常常会因为Linux服务器内存等信息出问题而导致服务不可用,因此监控服务器系统信息至关重要。
# 代码
#!/bin/bash
# 获取要监控的本地服务器IP地址
IP=`ifconfig | grep inet | grep -vE 'inet6|127.0.0.1' | awk '{print $2}'`
echo "IP地址:"$IP
# 获取cpu总核数
cpu_num=`grep -c "model name" /proc/cpuinfo`
echo "cpu总核数:"$cpu_num
# 1、获取CPU利用率
# 获取用户空间占用CPU百分比
cpu_user=`top -b -n 1 | grep Cpu | awk '{print $2}' | cut -f 1 -d "%"`
echo "用户空间占用CPU百分比:"$cpu_user
# 获取内核空间占用CPU百分比
cpu_system=`top -b -n 1 | grep Cpu | awk '{print $4}' | cut -f 1 -d "%"`
echo "内核空间占用CPU百分比:"$cpu_system
# 获取空闲CPU百分比
cpu_idle=`top -b -n 1 | grep Cpu | awk '{print $8}' | cut -f 1 -d "%"`
echo "空闲CPU百分比:"$cpu_idle
# 获取等待输入输出占CPU百分比
cpu_iowait=`top -b -n 1 | grep Cpu | awk '{print $10}' | cut -f 1 -d "%"`
echo "等待输入输出占CPU百分比:"$cpu_iowait
#2、获取CPU上下文切换和中断次数
# 获取CPU中断次数
cpu_interrupt=`vmstat -n 1 1 | sed -n 3p | awk '{print $11}'`
echo "CPU中断次数:"$cpu_interrupt
# 获取CPU上下文切换次数
cpu_context_switch=`vmstat -n 1 1 | sed -n 3p | awk '{print $12}'`
echo "CPU上下文切换次数:"$cpu_context_switch
#3、获取CPU负载信息
# 获取CPU15分钟前到现在的负载平均值
cpu_load_15min=`uptime | awk '{print $11}' | cut -f 1 -d ','`
echo "CPU 15分钟前到现在的负载平均值:"$cpu_load_15min
# 获取CPU5分钟前到现在的负载平均值
cpu_load_5min=`uptime | awk '{print $10}' | cut -f 1 -d ','`
echo "CPU 5分钟前到现在的负载平均值:"$cpu_load_5min
# 获取CPU1分钟前到现在的负载平均值
cpu_load_1min=`uptime | awk '{print $9}' | cut -f 1 -d ','`
echo "CPU 1分钟前到现在的负载平均值:"$cpu_load_1min
# 获取任务队列(就绪状态等待的进程数)
cpu_task_length=`vmstat -n 1 1 | sed -n 3p | awk '{print $1}'`
echo "CPU任务队列长度:"$cpu_task_length
#4、获取内存信息
# 获取物理内存总量
mem_total=`free | grep Mem | awk '{print $2}'`
echo "物理内存总量:"$mem_total
# 获取操作系统已使用内存总量
mem_sys_used=`free | grep Mem | awk '{print $3}'`
echo "已使用内存总量(操作系统):"$mem_sys_used
# 获取操作系统未使用内存总量
mem_sys_free=`free | grep Mem | awk '{print $4}'`
echo "剩余内存总量(操作系统):"$mem_sys_free
# 获取应用程序已使用的内存总量
mem_user_used=`free | sed -n 3p | awk '{print $3}'`
echo "已使用内存总量(应用程序):"$mem_user_used
# 获取应用程序未使用内存总量
mem_user_free=`free | sed -n 3p | awk '{print $4}'`
echo "剩余内存总量(应用程序):"$mem_user_free
# 获取交换分区总大小
mem_swap_total=`free | grep Swap | awk '{print $2}'`
echo "交换分区总大小:"$mem_swap_total
# 获取已使用交换分区大小
mem_swap_used=`free | grep Swap | awk '{print $3}'`
echo "已使用交换分区大小:"$mem_swap_used
# 获取剩余交换分区大小
mem_swap_free=`free | grep Swap | awk '{print $4}'`
echo "剩余交换分区大小:"$mem_swap_free
#5、获取磁盘I/O统计信息
echo "指定设备(/dev/sda)的统计信息"
# 每秒向设备发起的读请求次数
disk_sda_rs=`iostat -kx | grep sda| awk '{print $4}'`
echo "每秒向设备发起的读请求次数:"$disk_sda_rs
# 每秒向设备发起的写请求次数
disk_sda_ws=`iostat -kx | grep sda| awk '{print $5}'`
echo "每秒向设备发起的写请求次数:"$disk_sda_ws
# 向设备发起的I/O请求队列长度平均值
disk_sda_avgqu_sz=`iostat -kx | grep sda| awk '{print $9}'`
echo "向设备发起的I/O请求队列长度平均值"$disk_sda_avgqu_sz
# 每次向设备发起的I/O请求平均时间
disk_sda_await=`iostat -kx | grep sda| awk '{print $10}'`
echo "每次向设备发起的I/O请求平均时间:"$disk_sda_await
# 向设备发起的I/O服务时间均值
disk_sda_svctm=`iostat -kx | grep sda| awk '{print $11}'`
echo "向设备发起的I/O服务时间均值:"$disk_sda_svctm
# 向设备发起I/O请求的CPU时间百分占比
disk_sda_util=`iostat -kx | grep sda| awk '{print $12}'`
echo "向设备发起I/O请求的CPU时间百分占比:"$disk_sda_util
# 运行结果
IP地址:172.17.0.1 10.14.2.214
cpu总核数:4
用户空间占用CPU百分比:4.2
内核空间占用CPU百分比:6.2
空闲CPU百分比:90.3
等待输入输出占CPU百分比:0.0
CPU中断次数:0
CPU上下文切换次数:1
CPU 15分钟前到现在的负载平均值:1.70
CPU 5分钟前到现在的负载平均值:2.71
CPU 1分钟前到现在的负载平均值:average:
CPU任务队列长度:9
物理内存总量:24484376
已使用内存总量(操作系统):13464504
剩余内存总量(操作系统):8667688
已使用内存总量(应用程序):4482500
剩余内存总量(应用程序):3775032
交换分区总大小:8257532
已使用交换分区大小:4482500
剩余交换分区大小:3775032
指定设备(/dev/sda)的统计信息
sut.sh: line 91: iostat: command not found
每秒向设备发起的读请求次数:
sut.sh: line 95: iostat: command not found
每秒向设备发起的写请求次数:
sut.sh: line 99: iostat: command not found
向设备发起的I/O请求队列长度平均值
sut.sh: line 103: iostat: command not found
每次向设备发起的I/O请求平均时间:
sut.sh: line 107: iostat: command not found
向设备发起的I/O服务时间均值:
sut.sh: line 111: iostat: command not found
向设备发起I/O请求的CPU时间百分占比:
C →